 Kategorien
Kategorien
O-Notation – Akademischer Tag 1
Als ich in der Ideenschmiede den Vorschlag O-Notation gelesen habe, habe ich es fast nicht glauben können und schon vermutet, ich kenne ein PHP Feature namens O-Notation noch nicht. Doch es handelt sich wirklich um die mathematische O-Notation (oder Landau-Notation), die mit diesem Artikel auf Nils Wunsch hin den Blog auch mit etwas theoretischem Background erweitern soll.
Also was ist dieses 

Doch keine Angst, es ist wesentlich einfacher als es aussieht. Die O-Notation gibt an, wie komplex ein Algorithmus oder Codestück ist und wie es skaliert.
Ein klassisches Beispiel ist der BubbleSort Algorithmus, der ein Array von Zahlen sortiert. Er hat eine Komplexität von 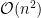


Zusätzlich vereinfacht die O-Notation die Angabe der Komplexität. Nehmen wir einmal an, ein Algorithmus benötigt 


Natürlich kann in dem O alles mögliche stehen und so gibt es natürlich auch 
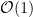
Vielen InformatikstudentInnen liegt vermutlich noch der Satz des Professors „Welche Komplexität hat dieser Algorithmus, schreiben Sie das in der O-Notation einmal auf“ im Nacken. Der Grund dafür ist jedoch nicht die Schwierigkeit der O-Notation an sich, sondern der Hintergrund. Um die O-Notation angeben zu können, muss man den Algorithmus verstehen und seine Komplexität abschätzen können. Leider denken viele Programmierer nicht über ihren eigenen Code nach und so werden einzelne Algorithmen oft zum schlecht skalierenden Flaschenhals. Ich bin der Meinung, dass auch in Zeiten von Profilern der Code mit Köpfchen erstellt werden sollte. Es kann also nicht schaden, wichtige Algorithmen ein paar Minuten zu analysieren und sich einmal zu überlegen, welche Komplexität denn wirklich dahinter steckt.
Warum brauche ich nun dieses komische
- Man kann vergleichen und verglichen werden. Im wissenschaftlichen Bereich ist es üblich, die Komplexität von neu entwickelten Algorithmen anzugeben um die Algorithmen vergleichbarer zu machen.
- Man befasst sich mit eigenen Algorithmen oder Abläufen und entdeckt so Fehler oder Verbesserungen
- Man lernt Einschätzungen zur Skalierung zu machen
- Man steht nicht unwissend da, wenn jemand einmal die O-Notation erwähnen sollte
- Und eigentlich der wichtigste Grund für den modernen Programmierer von Heute: Man kann mit seinem Wissen imponieren 😉
Zum Imponieren hier auch noch ein paar Begriffe zum googlen, die man unbedingt benötigt, um im Komplexitäts-Bullshit-Bingo zu bestehen:
– Notation
- Linear Speedup Theorem
- Asymptotische Laufzeitkomplexität
- Super- und Hyperexponentielle Komplexität
- O-Kalkül
- Landau-Symbole
- Definition des asymptotischen Maßes mit Limites
- Univariate Funktionen
Natürlich gibt es noch ganze Bücher hinter der O-Notation und ihrem mathematischen Hintergrund (siehe auch Bullshit-Bingo Liste). Dies würde aber natürlich den Rahmen dieses Blogs sprengen und so verabschiede ich mit 
Weiterführende Links:
http://www.linux-related.de/index.html?/coding/o-notation.htm
http://de.wikipedia.org/wiki/O-Notation
http://en.wikipedia.org/wiki/Big_O_notation
http://de.wikipedia.org/wiki/Komplexitätstheorie
http://mathworld.wolfram.com/AsymptoticNotation.html





Hat eigentlich irgendjemand Interesse an einer kleinen Einführung in Sachen LaTeX?
Ich habe das ganze zwar schon alles einmal in der Uni gehört, ist aber trotzdem schön es mal wieder ein wenig aufgefrischt zu haben. Danke dafür.
Die Aussage „Der derzeit beste vergleichsbasierte Sortieralgorithmus hat übrigens eine Komplexität von O(n*log(n))“ suggeriert, dass es vergleichsbasiert besser gehen könnte.
Bevor hier tatsächlich noch jemand versucht, einen schnelleren Algorithmus zu finden:
Jeder deterministische Sortieralgorithmus, der auf paarweisen Vergleichen von Schlüsseln basiert, benötigt zum Sortieren einer n-elementigen Liste von Elementen sowohl im Worst-Case als auch im Average-Case (bei Gleichverteilung) Omega(n*log(n)) Vergleiche.
Diese Abschätzung bezieht sich auf alle möglichen (vergleichsbasierten) Sortierverfahren, bekannte wie noch nicht unbekannte.
Danke für den Artikel, er hat mich in an ein spannendes Software-Projekt erinnert in dem der die Komplexität das entscheidende Problem war.
Danke für den Artikel!
Übrigens zur Aussage mit dem besten _vergleichsbasierten_ Sortieralgorithmus: Die Implikation, dass es noch andere Sortieralgorithmen gibt außer vergleichsbasierte ist korrekt, man kann auch anders sortieren (und dann auch durchaus in O(n), zum Beispiel mit dem RadixSort)! Dazu muss man allerdings einige Bedingungen erfüllen und benötigt mehr Speicher. Interessante Lektüre zu Algorithmen und IT-Themen aller Art (unbedingt anschauen!):
http://www.stefan-baur.de/index.contents.0.html
Passt gut, am Dienstag schreiben wir Algorithmen/Datenstrukturen Klausur und genau das ist eins der Themen.
Du könntest allerdings noch anhand einer geschachtelten Schleife demonstrieren, wie das in einem einfachen Beispiel berechnet wird.
Danke für die Kommentare. Zu den vergleichsbasierten Algorithmen, das stimmt natürlich, es geht nicht schneller und das ist formal auch bewiesen. Den eigentlich recht einfachen Beweis dazu findet man unter http://de.wikipedia.org/wiki/Sortierverfahren#Beweis_der_unteren_Schranke_f.C3.BCr_vergleichsbasiertes_Sortieren
ALso ich als Nicht-Informatik-Studierter komme da schon ein wenig ins Schleudern 🙂 Schön zu wissen, dass es das gibt und das es seine Berechtigung hat, aber anfangen kann ich damit jetzt erstmal gar nichts 😉
Ist aber auch mal interessant zu sehen, was denn so bei Theoretischer Informatik unterrichtet wird.
Hallo,
der Beitrag hat mir gut gefallen! Einblicke in die theoretische Informatik finde ich sehr interessant. Vor Allem die Begriffe und die weiterführenden Links find ich klasse! So kann ich noch ein wenig mein Imponiergehabe ausbauen 😉 😛
Ich hoffe den „Akademischen Tag“ gibt es in Zukunft öfter.
Viele Grüße
n3or
Ich habe mich schon öfter gefragt, wie das funktioniert und was dieses O eigentlich genau bedeutet. Jetzt bin ich schlauer. Vielen Dank für diesen super Artikel.
Den Kommentaren zu Folge, scheint der Akademische Tag wohl gut anzukommen. Freue mich etwas gefunden zu haben, was euch gefällt.
Super Artikel! Schlage mich damit gerade im Studium rum und freue mich auch mal soetwas in einem Blog zu lesen.
Über eine kleinen Einführung in Sachen LaTeX würde ich mich sehr freuen.
>> Hat eigentlich irgendjemand Interesse an einer kleinen Einführung in Sachen LaTeX?
joa, ich zum beispiel 🙂
Sehr fein zu lesen ! Aber vorallem klasse ums in der Firma rumzuschicken das man endlich „O(n)“ sagen kann und nichtmehr erklären muss was gemeint ist.
Super geschrieben
Super Artikel! Nur leider ist das Latex-Plugin deaktiviert, so dass er nicht ganz so einfach zum Lesen ist…
Geht nur mir das so, oder Fehlt dem Blog ein Parser-Plugin ([latex])? Ich kann die Funktionen so jedenfalls nicht lesen. :-/